We’ve received a PDF document, supposedly carrying a hidden message!
Task sounds pretty straightforward, doesn’t it? Let’s take a look at what we’re dealing with.
 First page with question marks, followed by two blank pages.
First page with question marks, followed by two blank pages.
So… what exactly can we do here? Let’s see if pdfinfo can tell us anything useful!
fox@fox-desktop:~/gyn$ pdfinfo mission_010.pdf
Producer: Skia/PDF m62
Tagged: no
UserProperties: no
Suspects: no
Form: none
JavaScript: no
Pages: 3
Encrypted: no
Page size: 612 x 792 pts (letter)
Page rot: 0
File size: 18312 bytes
Optimized: yes
PDF version: 1.5…nothing much, though it doesn’t seem there’s any JS present. At least this much. So, what to do next? Perhaps we can check if xref-table gives us a hint.
fox@fox-desktop:~/gyn$ qpdf --show-xref mission_010.pdf
1/0: uncompressed; offset = 17297
2/0: uncompressed; offset = 17481
3/0: uncompressed; offset = 17654
.
.
.
20/0: compressed; stream = 15, index = 4
21/0: compressed; stream = 15, index = 5Okay, plenty of things to look at, perhaps we can stumble upon something just checking a few of them.
fox@fox-desktop:~/gyn$ qpdf --show-object=1 mission_010.pdf
<< /Contents 2 0 R /MediaBox [ 0 0 612 792 ] /Parent 17 0 R
/Resources << /ExtGState << /G0 18 0 R >>
/ProcSets [ /PDF /Text /ImageB /ImageC /ImageI ] >> /Type /Page >>
fox@fox-desktop:~/gyn$ qpdf --show-object=11 mission_010.pdf
Object is stream. Dictionary:
<< /BitsPerComponent 8 /ColorSpace /DeviceRGB
/ColorTransform 0 /Filter /DCTDecode /Height 35
/Length 2905 /Subtype /Image /Type /XObject /Width 158 >>Hmm… An XObject! ImageB, ImageC, ImageI, Image… what if there was an actual image? You can embed a lot of things into a PDF, what if hidden image was one of the said things? At this point it’s just a wild guess, so let’s see where we’ll get with it. Now the question is, how do we want to inspect a PDF file in a manner that, maybe, could show us if there was a lost image somewhere? That’s where hex-editor may come in handy!
 Ha, there it is. A lonesome image!
Ha, there it is. A lonesome image!
Turns out inspecting PDF objects got us somewhere! Now, how do we retrieve the image? We’d need to know where its data begins and ends.
Lucikly, good ‘ol wikipedia got us covered.
JFIF file structure
Segment Code Description
SOI FF D8 Start of Image
. . . .
. . . .
EOI FF D9 End of ImageGreat, so now all we need is to copy the hex data starting with “FF D8” all the way until “FF D9”!
FF D8 FF E0 00 10 4A 46 ... D3 4D 11 34 D3 4D 11 34 D3 4D 11 34 D3 4D 11 7F FF D9Now just to make the data useful to us, in the end we want to find the hidden message!
xxd -r -p secret.txt secretjpg.jpg…and voila!
 our elusive hidden message
our elusive hidden message
Now that we’ve found it, although only due to a wild guess, could we find the solution easier and faster, without all the menial work?
Yes, we could’ve. If only I knew Origami came with pdfwalker. How easy it could’ve been?
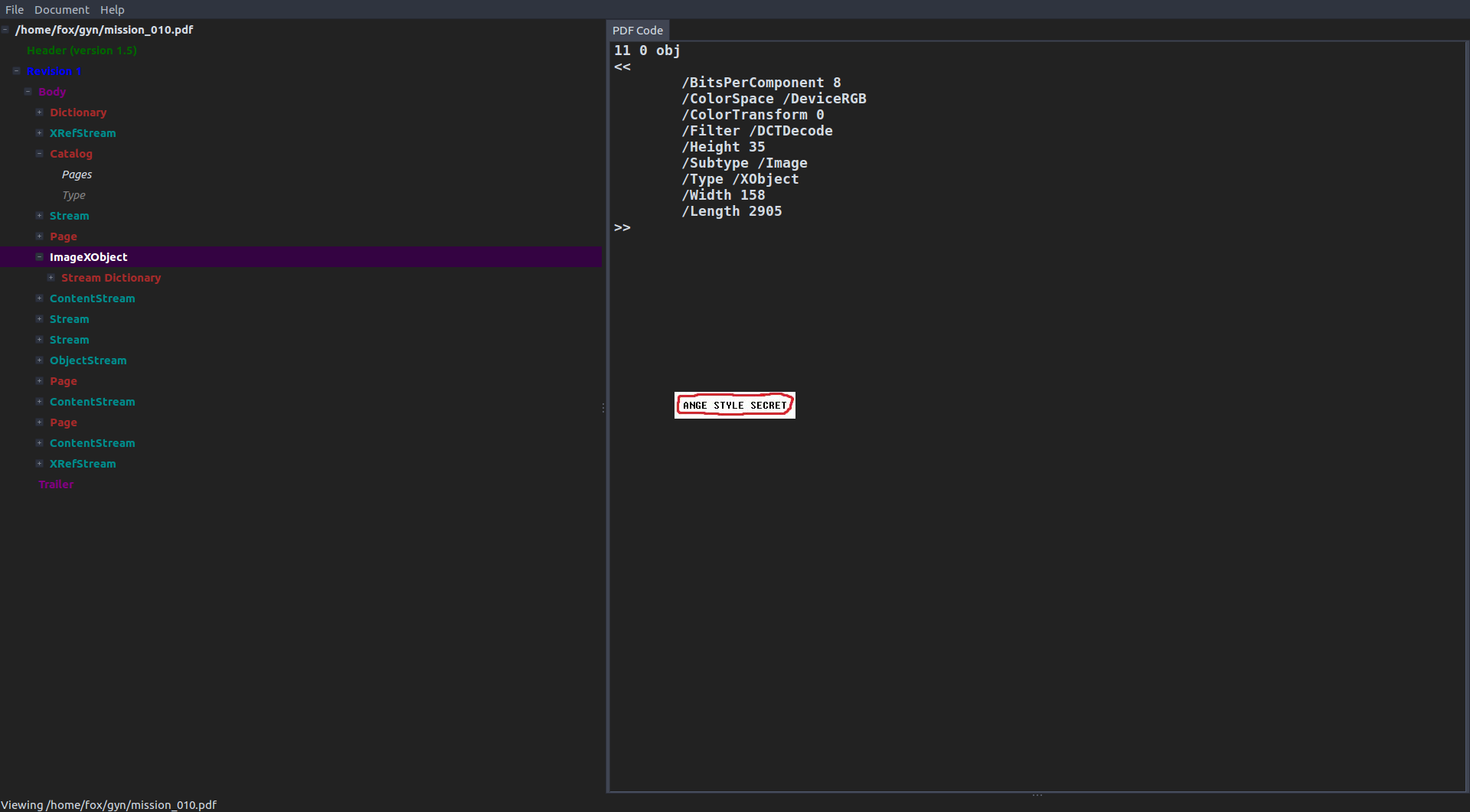 eh…very easy…
eh…very easy…